Just a few years ago, uploading large files could sound like an unfunny joke from Reddit:
 The last part of this joke may remind you of dealing with data on old iPhones.
The last part of this joke may remind you of dealing with data on old iPhones.
Now that networks have grown faster, we don't sweat over progress bars and rarely delete data to free up space. But the problem with large files is still there, because the sizes and the amounts of data we handle are growing exponentially.
So, if you plan to enable large file uploads for your end users or arrange a cozy off-site backup storage, there are some sensitive points to consider.
There is a historical twist to this question. In the late 90s, when most PCs and workstations ran on 32-bit operating systems, large files were files that couldn't be handled because of a physical memory barrier equal to 2 GB. Though we’re now in the era of 64-bit computing, the 2 GB file upload restriction is still valid for some HTTP web servers and the majority of browsers, except Google Chrome and Opera.
When it comes to other services, limits may significantly vary. For instance, 20-25 MB is the maximum size for a Gmail attachment. If a file is bigger, the service automatically loads it to Google Drive and offers to send a link. Even GitHub gives a warning if you want to upload a file larger than 50 MB and blocks pushes that exceed 100 MB, offering an open-source extension for large file storage (Git LFS).
But let’s come back to your task. If you wanted to enable large file uploads on your platform, either for your end users or for your team, you would probably look for a cloud storage provider like Google Cloud, Azure Blob, Dropbox, or Amazon S3.
The latter allows uploading objects up to 5 GB within a single operation and files up to 5 TB if split into chunks and processed by the API. This is quite enough even to upload an astonishing 200+ GB Call Of Duty game file or all the seasons of The Simpsons in one go. 😅
At Uploadcare, we receive more than 1 000 000 files every day from all over the globe, and consider files over 10 MB as large. Observing the trends, we can say that the size and the amount of media is growing by leaps and bounds, mainly thanks to the spread of video content.
Among the largest files processed through Uploadcare in 2020 there are mp4 and quicktime videos (up to 84 GB), and zipped photo archives.
We grouped the challenges a developer can run into when enabling large file uploads into two categories: issues related to low speed and latency, and upload errors. Let’s take a closer look at each of them and go over the possible solutions.
The larger a file, the more bandwidth and time it takes to upload. This rule seems logical for a developer but can become a huge pain point for an end user.
The biggest problem I came across was users wouldn't understand that it will take hours to upload a 5GB file
— Redditor /u/DiademBedfordshire
Speed problems usually occur if you transfer data in a single batch to your server. In this scenario, no matter where your end user is located, all the files go to a single destination via the same road, creating gridlock like in Manhattan during rush hour.
And if the files are huge, your channel gets paralyzed: the speed goes down, and you can’t use your assets to their full potential.
Possible solutions: 1) Set up multiple upload streams. 2) Use a distributed storage network and upload files to the closest data center.
All this could result in a nightmare of an infrastructure, if it weren’t for the major smart storage providers. At Uploadcare, we use Amazon S3, which receives numerous batches of data simultaneously and stores each of them in globally distributed edge locations. To increase the speed and latency even more, we use an acceleration feature that enables fast transfers between a browser and an S3 bucket.
By adopting this method, you can produce a reverse CDN wow effect: if a user is in Singapore, the uploaded data doesn't try to reach the primary AWS server in the US, but goes to the nearest data center, which is 73% faster.
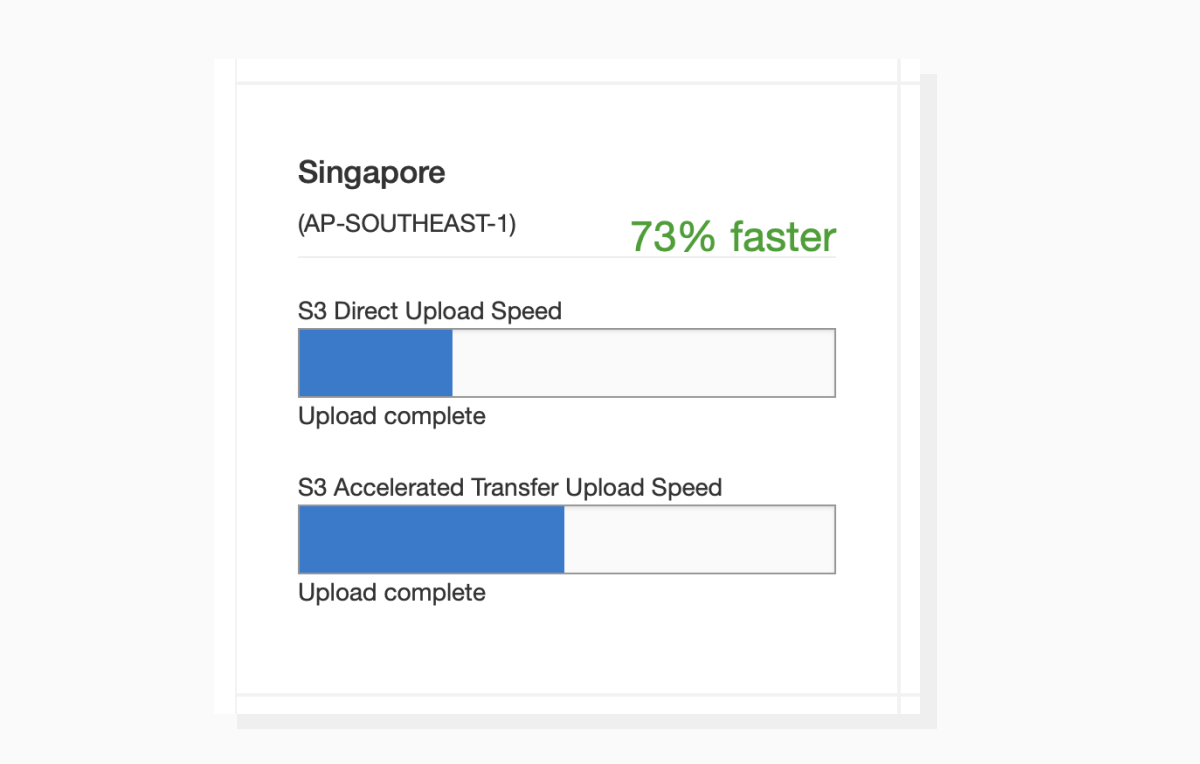 If you use the AWS Transfer Acceleration feature, the data will be uploaded significantly faster.
If you use the AWS Transfer Acceleration feature, the data will be uploaded significantly faster.
Check out the speed comparison and possible acceleration for your target regions in this speed checker.
The most common upload errors are due to limitations either on the user’s browser or your web server.
We’ve already talked about browsers: 2 GB is a safe maximum supported by all browser types and versions. As for a web server, it can reject a request:
- if it isn’t sent within the allotted timeout period;
- if memory usage limits are exceeded;
- if there’s a network interruption;
- if the client’s bandwidth is low or internet connection is unstable.
Possible solutions: 1) Configure maximum upload file size and memory limits for your server. 2) Upload large files in chunks. 3) Apply resumable file uploads.
Chunking is the most commonly used method to avoid errors and increase speed. By splitting a file into digestible parts, you overcome both browser and server limitations and can easily adopt resumability.
For instance, Uploadcare’s File Uploader splits all files larger than 10 MB into 5 MB chunks. Each of these chunks is uploaded in 4 batches simultaneously. This method maximizes channel capacity usage, prevents upload errors, and boosts upload speed by up to 4x.
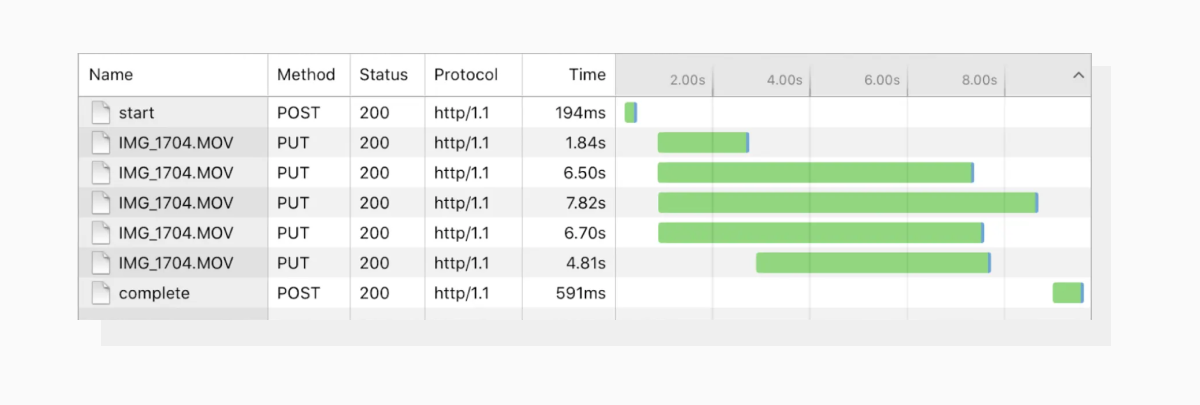 Uploadcare chunks all the files over 10 MB into 5 MB pieces and uploads them simultaneously in batches.
Uploadcare chunks all the files over 10 MB into 5 MB pieces and uploads them simultaneously in batches.
By performing multiple uploads instead of one, you become more flexible. If a large file upload is suspended for whatever reason, you can resume it from the missing chunks without having to start all over again. It’s no wonder that major user-generated media platforms like Facebook and YouTube have already developed resumable API protocols: with such diverse audiences, this is the only way to deliver no matter the individual user context.
There are around 168 GitHub repositories for resumable file uploads, but again, this method is already a part of major storage services like Google Cloud and AWS, or SaaS file handling solutions. So there’s no need to bother about forking and maintaining the code.
As always, there are three ways to go: 1) Build large file handling functionality from scratch. 2) Use open-code libraries and protocols. 3) Adopt SaaS solutions via low-code integrations.
If you choose to code yourself or use open-code solutions, you’ll have to think about:
- Where to store the uploaded files and how to arrange backups;
- How to mitigate the risks of low upload speed and upload errors;
- How to deliver uploaded files if needed;
- How to balance the load if you use your servers for uploads and delivery.
When it comes to SaaS solutions like Uploadcare, they take on the entire file handling process, from uploading and storing to delivery. On top of that:
- They use proven methods to upload and deliver fast. And their job is to enhance your performance every day.
- They support a wide range of use cases and spare you from troubleshooting.
- They provide legal protection and compliance.
- They ease the load on your servers and your team.
- They are maintenance free.
- They don’t uglify your code.
Case study: Supervision Assist is an application that helps to manage practicum and internship university programs. In particular, it allows university coordinators to supervise their students through live or recorded video sessions.
The company needed a secure HIPAA-compliant service that would handle large uncompressed files with recorded sessions in MP4, MOV, and other formats generated by cameras. The team managed to build such a system from scratch, but eventually got overwhelmed by upload errors, bugs, and overall maintenance.
If an upload didn’t complete, one of our devs would have to go look on the web server, see what data was stored and how much was there. Individually, it’s not a big deal, but over time that adds up.
— Maximillian Schwanekamp, CTO
By integrating Uploadcare, the company could seamlessly accept files of any format and as big as 5 TB without spending in-house development resources.
Apart from handling large file uploads, SaaS services can offer some additional perks like data validation, file compression and transformations, and video encoding. The latter allows adjusting the quality, format and size of a video, cutting it into pieces, and generating thumbnails.
There’s no universally accepted concrete definition of a “large file,” but every service or platform has its file handling limits. Uploading large files without respecting those limits or the individual user’s context may lead to timeouts, errors and low speed.
Several methods to face these problems include chunking, resumable uploads, and using distributed storage networks. They are successfully adopted by major smart storage providers and end-to-end SaaS services like Uploadcare, so you don’t need to build file handling infrastructure from scratch and bother about maintenance.