How to upload large files: A developer’s guide to handling and chunking large file uploads
Last edited:
Handling large file uploads is a common challenge for developers building applications that involve media storage, cloud backups, or large datasets. Uploadcare’s File Uploader provides robust solutions for managing these uploads efficiently. In this article, we will explore various techniques for handling large file uploads, with a focus on the API and HTTP aspects that are crucial for developers.
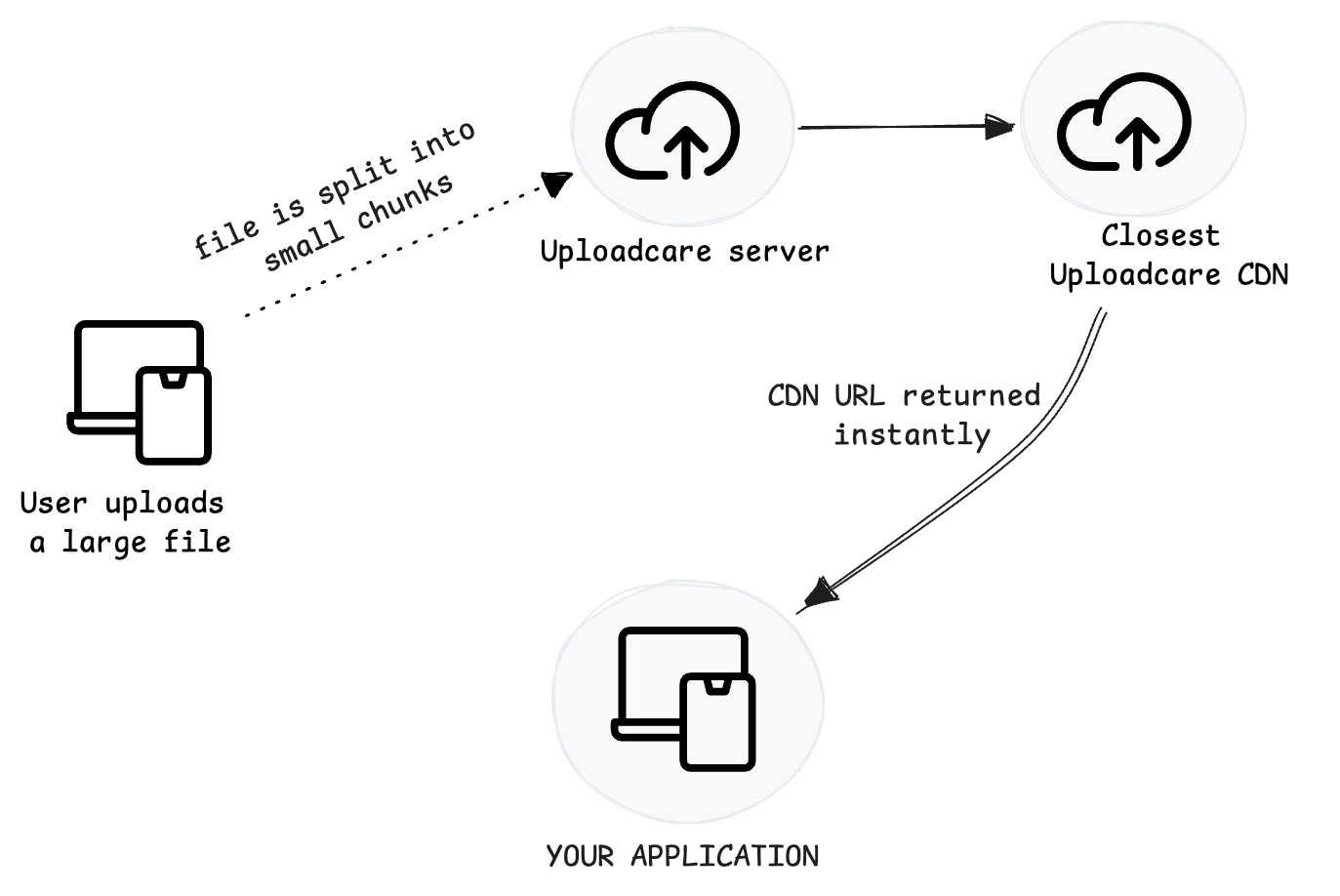 Large file uploading to Uploadcare servers
Large file uploading to Uploadcare serversWhat is considered a large file?
Most HTTP web servers usually limit file uploads to 1-16 MB by default, which is sufficient for most use cases.
Limits for other services may vary significantly. For instance, a Gmail attachment can be up to 25 MB in size. If a file is bigger, the service automatically loads it to Google Drive and offers to send a link.
Suppose you want to enable large file uploads on your applications, either for your end users or for your team. In that case, you might consider using a cloud storage provider such as Google Cloud, Azure Blob Storage, Dropbox, or Amazon S3.
Amazon S3 storage supports uploading objects of up to 5 GB in a single operation and files of up to 5 TB when divided into chunks and processed by the API. This is sufficient even for uploading very large files, such as those exceeding 200 GB, at once.
Depending on your project requirements and server configurations, you may also restrict large file uploads to a lower file size for improved UX, allowing users to avoid issues that come with uploading very large files.
Uploadcare, for example, receives millions of files daily from all over the world, including those larger than 10 MB and up to 5 TB.
Observing the patterns, it is clear that the size and quantity of media are expanding at a rapid pace, primarily due to the increase in video content.
Why uploading large files is challenging
When you allow large file uploads in your application, several intended and unintended challenges often arise since you cannot determine the location, device type, and network conditions that a user will use to upload a file in your application.
Upload speed, bandwidth, and latency
The larger a file, the more bandwidth and time it takes to upload. As a developer, this rule may seem logical to you, but it can be a huge pain point for an end user.
Upload speed problems usually occur if you transfer data in a single batch to your server. In this scenario, regardless of the end user’s location, all files are directed to a single destination via the same route, creating a traffic jam similar to that in Manhattan during rush hour.
When your users upload multiple large files simultaneously, it can cause your servers to become paralyzed: the speed decreases and the latency (the time it takes for the server to respond to requests) increases, especially if your server is not configured to handle large file uploads.
Upload failures and timeouts
When uploading a single large file, upload failures and timeouts may occur for various reasons:
- If there is a network interruption during the upload process
- If the file isn’t sent within the allotted timeout period
- If the user’s device doesn’t have enough memory to handle that large of a file
- If the server takes too long to respond to a request due to overload
- If the client’s bandwidth is low or the internet connection is unstable
Whatever the reason may be, upload failures are likely to occur if you do not handle large files properly.
Mobile & edge case constraint
Globally, a large majority of users access the internet via mobile devices, which often presents unique challenges and edge cases to consider when allowing large file uploads.
For one, mobile devices generally have slower network speeds and stricter data limits compared to wired connections, leading to issues such as timeouts and network interruptions.
What about in a situation where a user wants to switch between apps while uploading is happening, but the browser suspends background activities to conserve battery? Or it could be that the user’s device is in battery-saving mode, in which the mobile OS will aggressively shut down any non-essential tasks, thereby interrupting the upload process.
It is also possible that the device has limited storage or the OS has specific limitations that may cause issues with uploading large files. This could result in the device crashing or stalling uploads.
Server limitations
Handling large file uploads is not just about setting server configurations but also determining the maximum file size your server can handle.
Factors such as your server’s storage, memory, and the number of concurrent tasks it can handle simultaneously can be issues.
Yes, your server might be able to handle a single large file upload by default, but what happens when you have 1,000 users uploading large files simultaneously, and your server needs to process all of them?
Proven techniques for handling large file uploads
How do you handle large files and avoid problems related to large file uploads while ensuring your users have a good experience? The following techniques are some best practices for handling file uploads.
1. Chunk file uploads: Split large files into manageable parts
Chunking involves breaking a large file into smaller parts (chunks) and uploading them individually. This method allows for easier error management, as only the failed chunk needs to be re-uploaded. Additionally, chunking helps manage memory and bandwidth usage efficiently.
To implement chunking, you first need to split the large files into smaller chunks and upload them sequentially to your server. Next, you’ll need to set up a backend service to combine all the chunk files into the original file.
Once that is done, you can then return a response or the URL of the uploaded file to the frontend of your application, allowing users to access it.
For example, say you have an HTML form with an input that you would like to use for uploading large files (in this case, let’s consider a large file to be a file above 10 MB) with the markup:
<form id="upload-form">
<input type="file" id="file-upload">
<button type="submit">Upload file</button>
</form>Using JavaScript on the frontend, you can split the large file into smaller chunks and upload them individually using the code below:
document.getElementById('upload-form').addEventListener('submit', e => {
e.preventDefault();
uploadFile();
});
async function uploadFile() {
const fileInput = document.getElementById('file-upload');
const file = fileInput.files[0];
if (!file) {
alert('Please select a file to upload');
return;
}
const chunkSize = 5 * 1024 * 1024; // 5MB chunks
const totalChunks = Math.ceil(file.size / chunkSize);
const fileId = generateFileId(); // Generate unique ID for this upload
console.log(`Uploading file: ${file.name}, Size: ${file.size}, Chunks: ${totalChunks}`);
try {
// Upload all chunks
for (let chunkIndex = 0; chunkIndex < totalChunks; chunkIndex++) {
const start = chunkIndex * chunkSize;
const end = Math.min(start + chunkSize, file.size);
const chunk = file.slice(start, end);
await uploadChunk(chunk, chunkIndex, totalChunks, fileId, file.name);
// Update progress
const progress = ((chunkIndex + 1) / totalChunks) * 100;
console.log(`Upload progress: ${progress.toFixed(2)}%`);
}
await mergeChunks(fileId, totalChunks, file.name);
console.log('File upload completed successfully!');
} catch (error) {
console.error('Upload failed:', error);
}
}
async function uploadChunk(chunk, chunkIndex, totalChunks, fileId, fileName) {
const formData = new FormData();
formData.append('chunk', chunk);
formData.append('chunkIndex', chunkIndex);
formData.append('totalChunks', totalChunks);
formData.append('fileId', fileId);
formData.append('fileName', fileName);
const response = await fetch('/upload-chunk', {
method: 'POST',
body: formData
});
if (!response.ok) {
throw new Error(`Failed to upload chunk ${chunkIndex}`);
}
return response.json();
}
async function mergeChunks(fileId, totalChunks, fileName) {
const response = await fetch('/merge-chunks', {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify({
fileId,
totalChunks,
fileName
})
});
if (!response.ok) {
throw new Error('Failed to merge chunks');
}
return response.json();
}
function generateFileId() {
return Date.now().toString(36) + Math.random().toString(36);
}The code above splits a large file upload into smaller chunks (5 MB in size) and uploads them in bits to an HTTP API URL.
Now, there are three important functions in the code: uploadFile, uploadChunk, and mergeChunks.
I’ll show you what each one does and how they work together.
Let’s start with the uploadFile function, which is the main function that calls the other functions.
This function performs multiple steps for splitting the file:
- First, it gets the file from the form input.
- Then it generates a
fileIdfor the file, and using thechunkSizevariable of 5 MB, it calculates how many chunks the file can be split into. - Next, using the
Blob.slicemethod, it splits the file into various chunks, loops through each chunk, and for each chunk, calls theuploadChunkfunction. - When the
uploadChunkfunction has finished running, it then calls themergeChunksfunction.
The uploadChunk function is quite straightforward;
it creates a new FormData object and attaches all important information about the chunk file being uploaded to the FormData.
This information includes values like chunk, chunkIndex, totalChunks, fileId, and fileName.
It then sends a POST request using a Fetch API to the URL
/upload-chunk to upload each chunk file to the server.
When each chunk file has been uploaded successfully, the mergeChunks function is called.
This function uses the variables fileId, totalChunks, and fileName to send another request to the server
using the URL merge-chunks, this time to merge all the chunk files that were uploaded
and to retrieve the complete original file.
An example of how you might implement this in a Node.js backend that uses Express.js and expects to receive large files in chunks would look like this:
import express from 'express';
import multer from 'multer';
import fs from 'fs';
import path from 'path';
const app = express();
const PORT = 3000;
app.use(express.json());
app.use(express.static('public'));
// Create directories for uploads and temporary chunks
const uploadsDir = './uploads';
const chunksDir = './chunks';
fs.mkdirSync(uploadsDir, { recursive: true });
fs.mkdirSync(chunksDir, { recursive: true });
// Configure multer for chunk uploads with field parsing
const upload = multer({
storage: multer.diskStorage({
destination: (req, file, cb) => {
// Create a temporary directory first, we'll move the file later
const tempDir = path.join(chunksDir, 'temp');
fs.mkdirSync(tempDir, { recursive: true });
cb(null, tempDir);
},
filename: (req, file, cb) => {
// Use a temporary filename
cb(null, `temp-${Date.now()}-${Math.random().toString(36)}`);
},
}),
});
// Endpoint to upload individual chunks
app.post('/upload-chunk', upload.single('chunk'), (req, res) => {
const { fileId, chunkIndex, totalChunks } = req.body;
// Validate required fields after multer processes the request
if (!fileId) {
// Clean up the temporary file
if (req.file) {
fs.unlinkSync(req.file.path);
}
return res.status(400).json({ error: 'fileId is required' });
}
if (chunkIndex === undefined) {
// Clean up the temporary file
if (req.file) {
fs.unlinkSync(req.file.path);
}
return res.status(400).json({ error: 'chunkIndex is required' });
}
if (!req.file) {
return res.status(400).json({ error: 'No chunk uploaded' });
}
// Create the proper directory and move the file
const chunkDir = path.join(chunksDir, fileId);
fs.mkdirSync(chunkDir, { recursive: true });
const finalChunkPath = path.join(chunkDir, `chunk-${chunkIndex}`);
// Move the file from temp location to final location
fs.renameSync(req.file.path, finalChunkPath);
console.log(
`Received chunk ${chunkIndex} of ${totalChunks} for file ${fileId}`
);
res.json({
message: `Chunk ${chunkIndex} uploaded successfully`,
chunkIndex: parseInt(chunkIndex),
fileId,
});
});
// Endpoint to merge all chunks into the final file
app.post('/merge-chunks', async (req, res) => {
const { fileId, totalChunks, fileName } = req.body;
try {
const chunkDir = path.join(chunksDir, fileId);
const finalFilePath = path.join(uploadsDir, fileName);
// Create write stream for the final file
const writeStream = fs.createWriteStream(finalFilePath);
// Read and write chunks in order
for (let i = 0; i < totalChunks; i++) {
const chunkPath = path.join(chunkDir, `chunk-${i}`);
if (!fs.existsSync(chunkPath)) {
throw new Error(`Chunk ${i} is missing`);
}
const chunkData = fs.readFileSync(chunkPath);
writeStream.write(chunkData);
}
writeStream.end();
// Wait for the write stream to finish
await new Promise((resolve, reject) => {
writeStream.on('finish', resolve);
writeStream.on('error', reject);
});
// Clean up chunks directory
fs.rmSync(chunkDir, { recursive: true, force: true });
console.log(`File ${fileName} merged successfully`);
res.json({
message: 'File uploaded successfully',
fileName,
filePath: finalFilePath,
});
} catch (error) {
console.error('Error merging chunks:', error);
res.status(500).json({ error: 'Failed to merge chunks' });
}
});
app.listen(PORT, () => {
console.log(`Server running on http://localhost:${PORT}`);
});The backend code creates all the endpoints that are used by the frontend to upload all the chunk files.
It uses multer as middleware for catching each file in a request and processing the file before proceeding with the request.
Let’s look at each endpoint and how it handles it.
-
/upload-chunk: When a file is sent to this endpoint, it first checks if the file info is correct, and if it is, it creates a temporary directory named/chunksand uploads the chunk file there with thechunkIndexandfileIdattached to the file name so it knows the order of the chunks when it needs to merge them later. -
/merge-chunks: When the endpoint is requested, it first uses thefileIdto retrieve the uploaded chunks and then loops through them to create one single file using thefs.createWriteStreammethod.
This way it creates the original file that was uploaded and moves the file to the /uploads directory.
If you’d rather not implement chunking in your application from scratch, you could use a ready-made solution like Uploadcare’s File Uploader, which supports chunking out of the box.
2. Resumable uploads: Ensure reliability
Implementing resumable uploads helps maintain upload integrity in case of interruptions. It allows the upload to pause and resume without starting over. This technique is beneficial in environments with unstable network connections.
Resumable uploads allow users to pause and resume uploads at any time. This feature is particularly useful for large files, as it enables users to continue uploading from where they left off in case of network interruptions or other issues.
When implementing resumable uploads, include clear error messages and next steps to inform the user about what happened during the upload process and what to do next.
3. Streaming large files in real time
Another useful method is streaming, where the file is uploaded as it is being read. This is particularly beneficial for large files, as it lessens the stress on both the client and server and allows for continuous data transfer.
Some use cases where streaming a large file might come in handy are:
- Uploading very large media files in GBs, like 4k videos, game assets, or raw datasets
- Low RAM memory on the server or when you use a serverless environment for your backend
An example of this is using the createReadStream method in Node.js from the fs module to read files as they are being uploaded:
// example of streaming large file uploads in Node.js
const fs = require('fs');
const http = require('http');
const server = http.createServer((req, res) => {
const stream = fs.createReadStream('largefile.mp4');
stream.pipe(res);
});
server.listen(3000, () => console.log('Server running on port 3000'));4. Use a CDN and upload files to the closest data center
Using a Content Delivery Network (CDN) effectively handles large file uploads and ensures a smooth and reliable user experience. A CDN is a distributed server network that delivers content to users based on their geographic location.
By using a CDN for your backend services and ensuring files are uploaded to the closest data center, you can speed up the uploading of large files in your application by a significant amount.
At Uploadcare, we use Amazon S3, which receives numerous batches of data simultaneously and stores each in globally distributed edge locations. To increase speed and latency even further, we use an acceleration feature that enables fast transfers between a browser and an S3 bucket.
By adopting this method, you can produce a reverse CDN wow effect: if a user is in Singapore, the uploaded data doesn’t try to reach the primary AWS server in the US. Instead, it goes to the nearest data center, which is 73% faster.
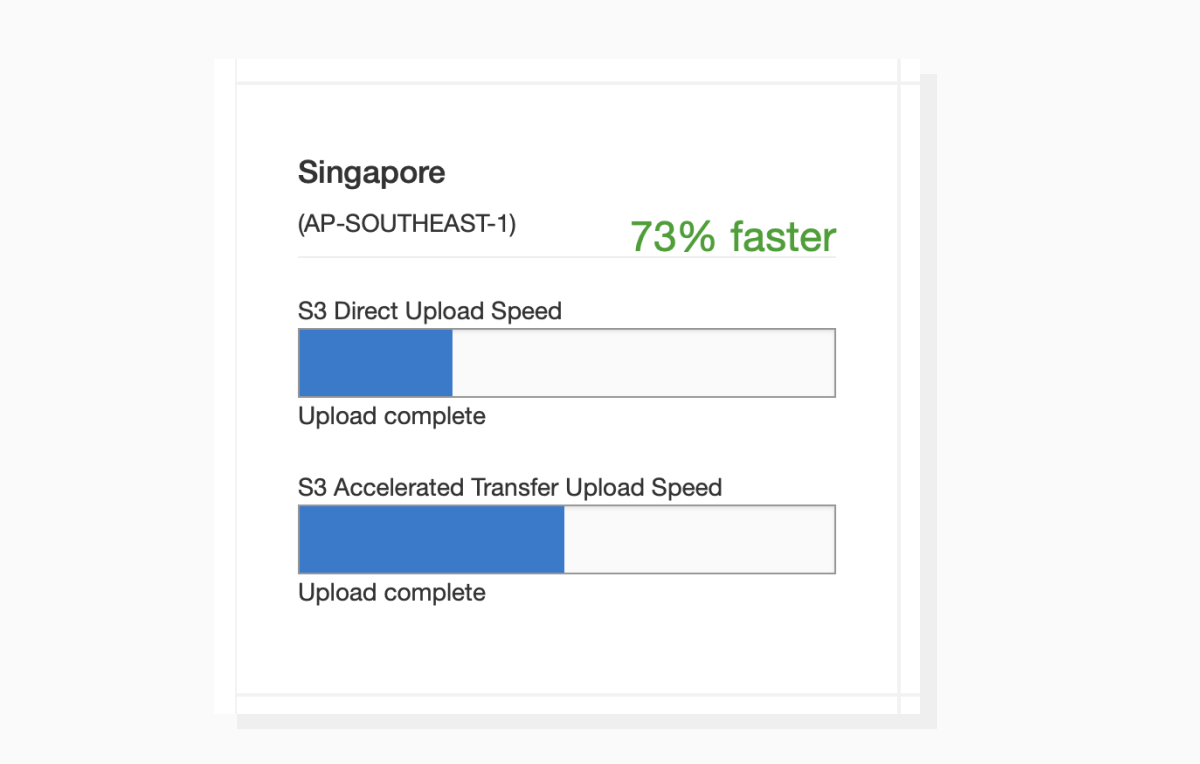 A speed estimate for uploading data to AWS with and without transfer acceleration feature
A speed estimate for uploading data to AWS with and without transfer acceleration featureCheck out the speed comparison and possible acceleration for your target regions in this speed checker.
Further readings on CDNs:
How Uploadcare helps handle large file uploads
Uploadcare’s File Uploader simplifies handling large file uploads with features like automatic chunking, resumable uploads, and error management. By integrating Uploadcare, you can leverage these capabilities to implement large file-uploading capabilities in your application and leave the heavy work to us.
You can integrate the File Uploader components from Uploadcare into your application:
<uc-config
ctx-name="my-uploader"
pubkey="YOUR_PUBLIC_KEY"
img-only="true"
multiple="true"
max-local-file-size-bytes="524288000"
use-cloud-image-editor="true"
source-list="local, url, camera, dropbox"
>
</uc-config>
<uc-file-uploader-regular ctx-name="my-uploader"></uc-file-uploader-regular>Some features Uploadcare provides for handling large file uploads include:
- Automatic splitting of large files into chunks by the File Uploader when uploading large files.
- Upload RESTful APIs and SDKs for uploading very large files in multipart (files above 100 MB) to Uploadcare servers.
- Files are distributed across multiple global CDNs, ensuring fast access and download speeds for your users worldwide.
- All uploads are made via secure HTTPS, ensuring secure data transfer. Fine-grained access controls and permissions can be set to manage who can upload, view, or modify files.
Case study: Supervision Assist is a platform that helps universities manage practicum and internship programs by enabling coordinators to supervise students through live or recorded video sessions. To support this, the team initially built a custom, HIPAA-compliant upload system for handling large, uncompressed video files (MP4, MOV, etc.), but it became increasingly difficult to maintain due to frequent upload errors, bugs, and infrastructure challenges.
If an upload didn’t complete, one of our devs would have to go look on the web server, see what data was stored and how much was there. Individually, it’s not a big deal, but over time that adds up.
— Maximillian Schwanekamp, CTO
By integrating Uploadcare, the company could seamlessly accept files of any format and as big as 5 TB without spending in-house development resources.
👉 Read the full case study on how Supervision Assist improved their file upload process with Uploadcare.
Apart from handling large file uploads, using a service like Uploadcare can offer some additional perks like data validation, file compression and image process, and video encoding. The latter allows adjusting the quality, format and size of a video, cutting it into pieces, and generating thumbnails.
Real-world use cases and best practices
Some real-world use cases where you may need to handle very large files might include:
- Uploading large videos, like for educational or media & entertainment platforms, where content has to be sharp and of high resolution
- Analytics tools where users deal with large dataset files, such as large CSV and Excel sheet files
- Applications where you need to handle customer-generated content, allowing your customers/users to upload things like videos, images, audio, and other files
Best practices
Some best practices to follow include:
- Use combined chunked uploading with resumable uploads to create file uploading processes that can handle large files with improved fault tolerance.
- Always show upload progress and status to give users an idea of what is currently going on with the file uploading process.
- Always clean up temporary files or partial uploads from your server, as this can quickly clog your server’s storage and drain performance.
- Set file limits on how large of a file can be uploaded to prevent issues like resource exhaustion and poor UX performance. You can set limits like max size, file type, and timeout limit both on the frontend and backend of your application.
Pro tip: In your code, validate the files early (before upload) to save bandwidth and avoid unnecessary work.
Conclusion: What’s the best way to handle large file uploads?
There’s no universally accepted definition of a “large file,” but every service or platform has file handling limits. Uploading large files without respecting those limits or the individual user’s context may lead to timeouts, errors, and low speed.
By utilizing techniques such as chunking, streaming, and resumable uploads, you can ensure that your application efficiently and reliably handles any large file uploads that are thrown at it. Additionally, where possible, consider integrating a battle-tested solution like Uploadcare to leverage these methods without having to bother about the complexity of building from scratch.
Try out Uploadcare’s File Uploader for free today and handle large files with ease.
For more information on secure file uploads, check out our blog post on secure file uploads.