Vulnerability in HTML design: the script tag
Last edited:
TL;DR
This article covers one of the ways to avoid the by-design <script> HTML element vulnerability.
Long story short, unlike any other HTML tag, <script> implies different rules of escaping its content. The proper escaping is unreasonably difficult and can even be impossible under certain circumstances.
The “escaping problem” often makes <script> a source of security vulnerabilities in HTML.
Instead of going with the uncertain rules, I propose using the <safescript> element which follows HTML guidelines on escaping via HTML entities.
🔖 Now, read on to check out all the details.
Introduction
There was a time when most web pages were manually crafted by programmers. These days, a greater part of the code delivered to client browsers is either generated or processed by robots. Those robots and the building blocks they use should be reliable and secure.
It’s 2020, and an HTML element used by every developer contains vulnerabilities at its core.
To begin with, I want to briefly describe how the HTML parser works. HTML is a hypertext markup language, and if you want to properly “speak” that language, you should follow the specs. Otherwise, the one “listening” to you just won’t understand what you’ve got to say. Now, let’s take a look at an example with HTML attributes:
<tagname attributename="value">In the above example, the element tagname has a single attribute named attributename. The attribute’s name is followed by an equals sign. After the sign is a value surrounded by double quotes.
This will change if we put in "LLC "Horns and Hoofs"." in the value. The element will then have four attributes: an attributename with "LLC " in its value and three additional ones named: Horns, and, and Hoofs".". All with empty values.
<tagname attributename="LLC "Horns and Hoofs".">The HTML specification allows you to escape special symbols: that is, make a parser read them as just characters. For quotes, you can use the " symbol sequence. Such sequences are called HTML entities.
<tagname attributename="LLC "Horns and Hoofs".">With that in mind, if you had the " symbol sequence in your initial string and didn’t want the parser to interpret it as a quote, you could go with & instead of just &, i.e., &quot;.
Thus, the transformation of our input string into the output is consistent and reversible. So, we can read and write any data as attribute values without any inspection of their actual content. You follow the rules and everything works out fine and dandy. The end.
Most formats we encounter work in a similar fashion: there is some syntax, a way to escape content from it, and a way to avoid the so-called “escape characters” from being parsed as special symbols. Again, this is true for most formats, but not…
The <script> tag — A source of vulnerability in HTML
<script> serves the purpose of embedding code fragments written in other languages in HTML. These days, in 99% percent of cases that would be JavaScript. The embedded script starts right after the opening <script> tag and ends right before the closing one, </script>. The HTML parser doesn’t even look inside the tag. It passes its contents to a JS parser.
In turn, JavaScript is an independent and self-sufficient programming language. It wasn’t designed in any specific manner to be embedded in HTML. It’s got its own string literals that can hold whatever content. And, as you may have already guessed, there might be a sequence of characters that stands for the closing </script> tag.
<script>
var s = "surprise!</script><script>alert('whoops!')</script>";
</script>What should be happening here is the variable s being assigned some harmless string value. However, what happens is the script where we declare s terminates with var s = "surprise!. This generates a syntax error. All further text is interpreted as pure HTML with any injected markup. In our case, there is a new opening <script> tag that executes some malicious code.
We now have the same effect as if there was a double quote in the HTML attribute value. You might think of using HTML entities, but they wouldn’t help in this case.
<script>
var s = "surprise!</script><script>alert('whoops!')</script>";
</script>Taking into consideration how the HTML parser works within <script>, your string now holds HTML entities, which means the contained data was altered.
In contrast with the quote that can be escaped from the string, the <script> tag doesn’t provide any way to escape its content. The HTML standard itself states that there should be no </script> symbol sequence within the <script> tag. However, the JavaScript specification doesn’t forbid using such character sequences in string literals.
The result here is counterintuitive: after embedding a valid JS in a valid HTML on a valid basis, we get an invalid result.
That’s the HTML vulnerability I’m talking about; it leads to some real issues in existing applications.
Exploiting the HTML vulnerability
No doubt, it’s hard to imagine that you’ll see no problems when manually writing some code and putting </script> there. At the bare minimum, your syntax highlighting will show that the tag closed earlier than expected. Or, you just won’t be able to properly execute the code and will have to spend some time fixing it. So, that’s not where the real problem lies.
Modern app development is often about dynamically generating HTML including <script> content. Here’s a code snippet you can frequently encounter in apps using Redux with server-side rendering:
<script>
window.__INITIAL_STATE__ = <%- JSON.stringify(initialState) %>;
</script></script> may appear in any position within initialState where you get data from users or systems. JSON.stringify() won’t be alerting such strings on serialization: they’re fully compliant with both the JSON and JavaScript specs. Thus, such lines will jump into your page and allow the intruder to execute any JS code in a user’s browser. Here’s another example:
<script>
analytics.identify(
'<%= user.id %>',
'<%= request.HTTP_REFERER %>',
// ...
);
</script>In the example above, we get user id and referer written into strings. A template processor will then escape the values in line with the JS specs. And, while user id will almost certainly contain nothing but digits, an intruder might insert the </script> tag into referer.
The fun has only just begun with the closing </script> tag. Another implication is related to the opening <script> tag if there is the <!-- combination somewhere before it. In HTML, that usually starts a multi-line comment. There won’t be much help from your highlighted syntax either. Now, take a look at the following snippet:
<script>
var a = 'Consider this string: <!--';
var b = '<script>';
</script>
<p>Any text</p>
<script>
var s = 'another script';
</script>What a regular person sees here is two <script> tags and a paragraph of text. Now, what about the weird HTML parser? It sees just a single unclosed <script> tag holding everything from the second line to the very end.
I can’t say I completely understand why it works this way, but once encountering <!--, the HTML parser starts counting the opening and closing <script> tags and doesn’t consider the script terminated until all of the opened scripts are closed. Thus, in most cases, a script will last until the very end of the page; well, unless someone happens to inject another closing </script> using another website vulnerability. If you haven’t seen that yourself, you might even think I was joking. However, I wasn’t.
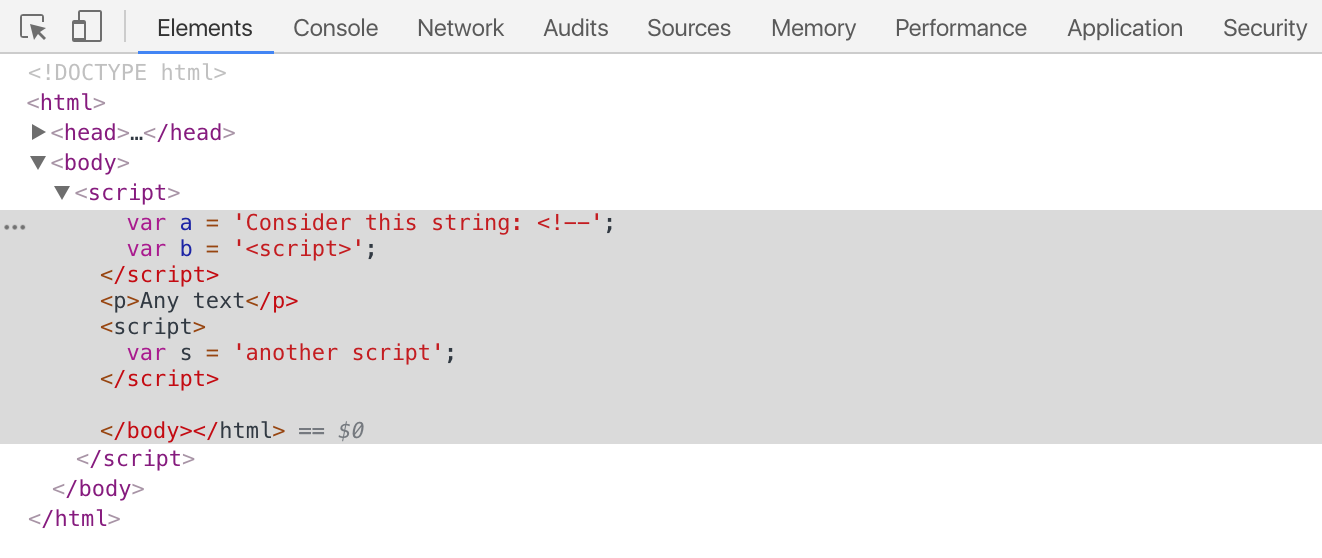 Here’s the DOM tree screenshot.
Here’s the DOM tree screenshot.The worst thing here is that even though </script> in JavaScript can only be encountered in string literals, <!-- and <script> can sit somewhere in the code and have the same effect:
<script>
if (x<!--y) { ... }
if (player<script) { ... }
</script>Erm, are you really a specification?
The HTML specs not only forbid you from using valid symbol sequences in the <script> tag and don’t provide you with any way to escape them within the scope of HTML, the following is stated there:
The easiest and safest way to avoid the rather strange restrictions described in this section is to always escape
<!--as<!--,<scriptas<script>, and</scriptas</scriptwhen these sequences appear in literals in scripts (e.g. in strings, regular expressions, or comments), and to avoid writing code that uses such constructs in expressions.
That recommendation makes at least three naive assumptions about how we use HTML:
- In a script you embed (which is not necessarily JavaScript), such symbol sequences can either sit strictly within script literals or can easily be avoided in the language syntax.
- In the embedded script, you can escape the symbol sequences, and this will not alter their syntax meaning.
- Someone embedding a script knows what that script is, understands its constructs, and can properly mutate it.
While the first two points are okay with JavaScript, the third point isn’t.
Scripts are not always embedded by a skilled person. Embedding is often handled by HTML generators.
For instance, here’s an example of how a browser is unable to handle it:
var script = document.createElement('script')
script.innerText = 'var s = "</script><script>alert(\'whoops!\')</script>"';
console.log(script.outerHTML);
>>> <script>var s = "</script><script>alert('whoops!')</script>"</script>As you can see, the serialized string was not parsed into an element equivalent to the original. Transforming a DOM tree to HTML text is not consistent and reversible in the general case. Some DOM trees just can’t be interpreted as their source HTML.
How to avoid the HTML injection vulnerability
As you have already come to understand, there’s no safe way of embedding JavaScript in HTML. However, there is a way of making JavaScript safe for embedding in HTML (now, hold on for a moment and feel the difference).
Of course, the latter would force you to be extremely cautious when writing stuff in your <script>. Especially when you insert something via a template processor.
The truth is, the possibility of encountering <!-- and/or <script> in your source code is pretty low, even in its minified version. You probably won’t code something like that, and if an intruder happens to inject something in your <script>, that will bother you at the last moment.
There still exists the problem of injecting symbols in strings. In such a case, you follow the specs: escape everything as stated. However, the problem is after you do JSON.stringify(), you won’t want to parse the output again and find all the string literals to escape stuff. Also, I wouldn’t advise using third-party serialization packages to tackle the problem: cases may vary, and you want to be safe at all times. Thus, I would advise escaping < with a Unicode escape sequence after serialization. Such symbols can’t be encountered anywhere in JSON, but they can be found within string literals, so simply replacing symbols would be safe enough.
<script>
window.__INITIAL_STATE__ = <%- JSON.stringify(initialState).replace(/</g, '\\u003c') %>;
</script>You may want to escape < via HTML entities. This helps you get rid of the HTML injection vulnerability, but your data is now spoiled. Hence, you should choose the right way of escaping for every encountered case, and that’s a hassle.
You can also escape individual strings in the same manner. Another bit of advice is not to embed anything via a <script> tag. Store your data in places where escape transformations are predictable and reversible, like in other elements’ attributes. However, this lacks visual clarity and only works for strings: JSON would have to be parsed separately.
<var id="s" data="surprise!</script><script>alert("whoops!")</script>"></var>
<script>
var s = document.getElementById('s').getAttribute('data');
console.log(s);
</script>If, despite your best efforts, you’re still afraid of being hacked, you can forbid executing anything except the scripts you allow explicitly. To do that, add a nonce (number used once) attribute containing some unique value and a special header that forbids executing scripts without that attribute.
Then, even if an intruder happens to inject a malicious script into your page, the script will not be executed. This is called Content-Security-Policy.
In the end, if you want to comfortably develop web apps and not wander around minefields, you need a reliable way of embedding scripts in your HTML. I propose dumping the <script> tag entirely, since it’s just too unpredictable.
The <safescript> tag
Let’s be honest here: we can abandon embedded scripts completely. But what next? Always connecting external scripts can’t be an option here, because it’s pretty convenient to have scripts and their data in a single HTML. You can then have fewer HTTP requests and server-side routes.
What I suggest is implementing a separate tag: <safescript>. All the content of <safescript> would follow the HTML specs: we get fully working HTML entities for escaping char sequences, thus making any embedded script safe.
<safescript>
var s = "surprise!</script><script>alert('whoops!')</script>";
</safescript>
<safescript>
var a = 'Consider this string: <!--';
var b = '<script>';
</safescript>The code within <safescript> may look a bit unusual, but that’s what will sit in your HTML. You can add a simple filter to your template processor that will insert the tag and escape every needed char sequence. Here’s what the code might look like in Django:
{% safescript %}
var s = "surprise!</script><script>alert('whoops!')</script>";
{% endsafescript %}
{% safescript %}
var a = 'Consider this string: <!--';
var b = '<script>';
{% endsafescript %}It’s not necessary to wait until browsers have <safescript> supported: I made a simple polyfill that just works. Here’s how you implement it:
<script type="text/javascript" src="/static/safescript.js"></script>
<style type="text/css">safescript {display: none !important}</style>Conclusion
Embedding scripts in HTML is tricky. Most of the time, you need to be very careful not to open up a security vulnerability in your website. And, there are cases when embedding scripts in HTML should be avoided; that’s mostly related to dynamically generated HTML.
However, you can use the proposed <safescript> tag to embed any script. This approach lets you forget about escaping in JavaScript and avoid many web vulnerabilities. Also, it’d be cool to add <safescript> to the general HTML specification or devise some other way of handling the problem of embedding scripts in HTML.