How Uploadcare built a stack to handle 500M file API requests per day
Last edited:
This article was first published on Stackshare in 2017. It was reviewed and updated in August, 2021.
Uploadcare is a file infrastructure as a service solution. We offer file-handling building blocks that provide simple controls for managing complex technologies. These controls include our File Uploader, Upload API, REST API, and CDN API. Altogether, these APIs handle 500M requests per day.
Simply by adding a few lines of code, you gain the capabilities to upload, store, process, cache, and deliver files. Our users can upload files directly to their own storage, and we support uploads from Dropbox, Facebook, and many other external sources.
Uploading and editing files in File Uploader
Yes, technically you can get a basic file-handling system up and running pretty fast, and handle files on your own. Still, it’s not that simple. What about storage? Uptime? A clear and friendly UI? Fast delivery to remote regions? Security, privacy, compliance? For most of the use cases we analyzed, there’s no sense investing in developing your own file infrastructure.
Setting up Uploadcare is quick, and handles many of the common issues users face when handling both large files and batches of smaller ones. Plus — and this is a big deal — you don’t need to test your system in every browser and maintain the infrastructure.
Uploadcare has built an infinitely scalable infrastructure by leveraging AWS. Building on top of AWS allows us to process 500M daily requests for file uploads, manipulations, and deliveries. When we started in 2011, the only cloud alternative to AWS was Google App Engine, which was (at that time) a no-go for the rather complex solution we wanted to build. We also didn’t want to buy any hardware or use co-locations.
Our stack handles receiving files, communicating with external file sources, managing file storage, managing user and file data, processing files, file caching and delivery, and managing user interface dashboards.
From the beginning, we built Uploadcare with a microservice-based architecture.
Here’s a breakdown of the solutions we use in our stack:
Backend
At its core, Uploadcare runs on Python. We were really inspired by Python as a solution when we went to the Europython 2011 conference in Florence, and our decision was informed by the fact that it was versatile enough to meet all of our challenges. Additionally, we had prior experience working in Python.
We chose to build the main application with Django because of its feature completeness and large footprint within the Python ecosystem.All communications within our ecosystem are handled via several HTTP APIs, Redis, Amazon S3, and Amazon DynamoDB. We decided on this architecture so that our system could be scalable in terms of storage and database throughput. This way, we only need Django running on top of our database cluster. We use PostgreSQL as our database, because it’s considered an industry standard when it comes to clustering and scaling.
Uploads, external sources
Uploadcare lets users upload files using our jQuery File Uploader. We support multiple upload sources including APIs that only require URLs.
Uploaded files are received by the Django app, where the majority of the heavy lifting is done by Celery. It’s great for handling queues, and it’s got a great community with tons of tutorials and examples to leverage. Celery handles uploading large files, retrieving files from different upload sources, and storing files, and pushes files to Amazon S3 as well as numerous other housekeeping jobs. All the services Uploadcare provides are handled by separate Amazon EC2 autoscaling groups and are covered by AWS Elastic Load Balancing (ELB), so the services automatically adjust their capacity to handle any number of requests, and thus ensure better availability.
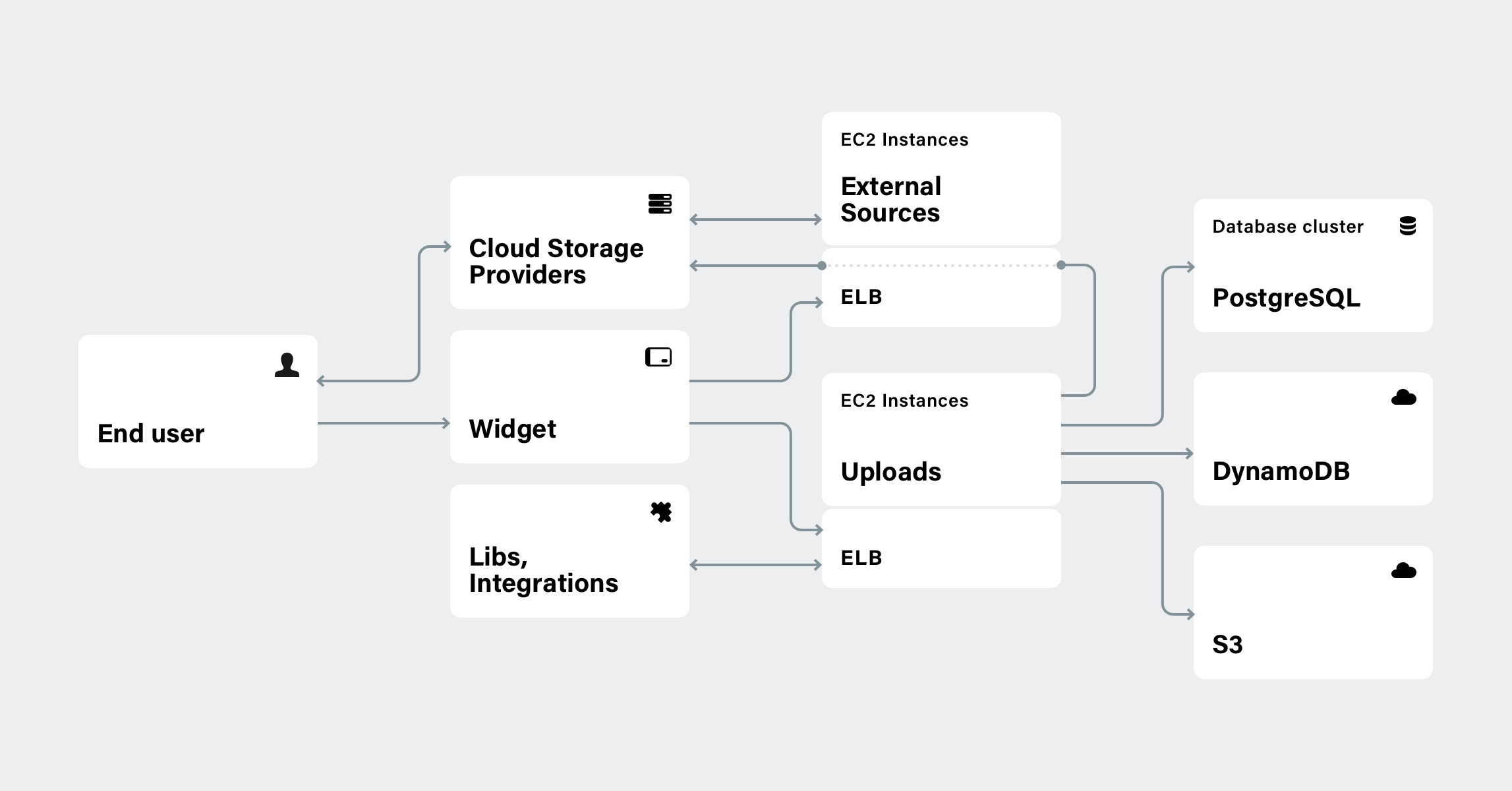 All Uploadcare services are handled by separate EC2 autoscaling groups and are covered by ELB
All Uploadcare services are handled by separate EC2 autoscaling groups and are covered by ELBThe only two issues we have experienced with AWS were inaccurate reports from the AWS status page, and failing to plan ahead when reserving resources to reduce costs and inefficiencies. The latter issue, though, was resolved; the latest AWS web services are good at tackling this task.
File storage, user and file data
We use Amazon S3 for storing files at rest. The EC2 upload instances, REST API, and processing layer all communicate with S3 directly. S3 gives us the ability to store customer files forever if they want.
File and user data are managed with a heavily customized Django REST framework. At first, we used the out-of-the-box Django REST framework, since it helped us to rapidly deploy features. However, as our vision of how a REST API should work evolved, we implemented customizations to fit our use cases. The footprint of our custom additions has grown large enough that updating the framework is a pain point. We're looking to modify this part of our stack to avoid adding further customizations that would compound this problem.
We use Flask to handle communication with social networks and cloud storage service (sources), as well as OAuth communications. It’s lightweight and efficient and doesn’t include any features that we don’t need, such as queues, an ORM layer, or caches. We explore this topic in more detail in an article on cloud security on our blog explaining how Uploadcare gets content from social media and how we treat end users’ privacy.
Processing
The 500M API requests we handle daily include many processing tasks, such as image enhancements, resizing, filtering, face recognition, and GIF-to-video conversions. Our file processing requirements necessitate using asynchronous frameworks for IO-bound tasks. Tornado is the one we currently use. Plus, we utilize aiohttp for Media Proxy.
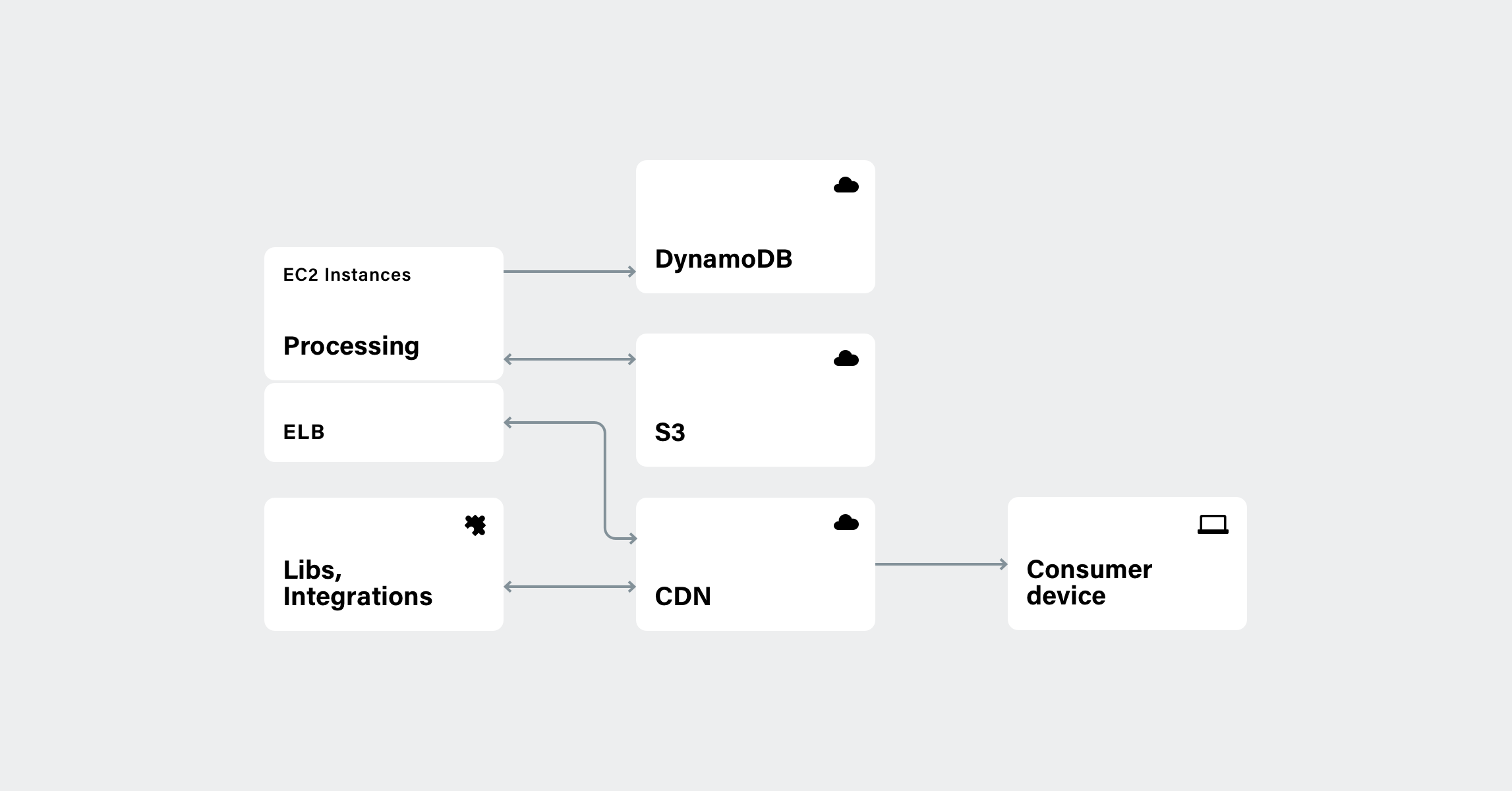 Backend processing scheme
Backend processing schemeOur real-time image processing is a CPU-bound task. Since Python is at the heart of our service, we initially used PIL, followed by Pillow. We kind of still do. When we figured out that resizing was the most taxing processing operation, Alex Karpinsky, an Uploadcare engineer, created a fork named Pillow-SIMD and implemented a good number of optimizations into it to make it 15 times faster than ImageMagick. Thanks to the optimizations, Uploadcare now needs six times less computing power, so we can use both fewer and smaller EC2 instances. The processing instances are also paired with ELB, which helps ingest files into the CDN.
Caching, delivery
There are three layers of caching, which help improve the overall performance:
- Caching in the processing engine so that the same operations are not run many times
- Caching inside CDN Shield so CDN edges cache things more effectively and don’t hammer origin servers
- Caching on the CDN edges as the frontier closest to consumer devices
For delivery, files are then pushed to Akamai CDN with the help of nginx and AWS Elastic Load Balancing. We also use Amazon CloudFront and KeyCDN, but due to the lack of coverage, we moved to Akamai as our default CDN.
It's also worth adding that our file receive/deliver ratio is strongly biased toward delivery.
Frontend
Simple controls over complex technologies, as we put it, wouldn't be possible without neat UIs for our user areas, including start page, dashboard, settings, and docs.
Initially, there was Django. Back in 2011, considering our Python-centric approach, that was the best choice. Later, we realized we needed to iterate on our website more quickly. This led us to detaching Django from our frontend. That was when we decided to build an SPA.
Building an SPA for our main page, docs, and other site sections from scratch is an ongoing process. It's done with Node.js, which is asynchronous and provides isomorphic rendering. In order to communicate with our older Django-based frontend, it uses JSON API through nginx, and that's a rule of thumb we stick to: once separated, the communications between our frontend and backend will still be carried out via JSON API.
We use React and many elements of its ecosystem for building most user interfaces. This library has become the industry standard, but we continue to explore the capabilities of different web platforms, in case there’s something more exciting on the horizon. At the moment, we’re looking closely at new browser APIs, such as Custom Elements and Shadow DOM, which allow us to reconsider the ease of integration for our solutions.
For implementing the embedded components, we decided to use the LitElement library, seasoned with our own additions based on our experience working with data.
For project assembly, we utilize Rollup, Webpack, and some mainstream techniques for code delivery optimization, such as tree shaking, lazy loading, and code splitting.
As for the static site pages, many of them are Markdown-formatted files sitting in a GitHub repo. Overall, we’re using a GitHub Pull Request Model for deployment. The files from the repo then go through jinja2-inspired nunjucks followed by markdown-it and posthtml. Our docs are built this way, for instance.
For styles, we use PostCSS along with its plugins such as cssnano, which minifies all the code.
As you can tell, we like the idea of post-processors. posthtml, for instance is a parser and stringifier that provides an Abstract Syntax Tree which is easy to work with.
All that allows us to provide a great user experience and quickly implement changes where they’re needed with as little code as possible.
Deployment
As I mentioned above, we use the GitHub Pull Request Model. Certain parts of the process are automatic, while others require manual intervention. We use the following steps:
- We create a branch in a repo with one of our features.
- Commits are made to the branch. That’s followed by automatic tests in TeamCity.
- If the tests pass, a PR is created, followed by both auto tests and code review by the dev team.
- If tests pass/review okay, we merge the changes to the staging branch, which is then automatically deployed via TeamCity and Chef.
- When deployed, we run integration tests via TeamCity.
- If everything is green, we merge changes to the production branch and run one more battery of tests automatically via TeamCity.
- If the tests pass and it’s not a Friday night, we deploy to production. Chef scripts here are run by devops.
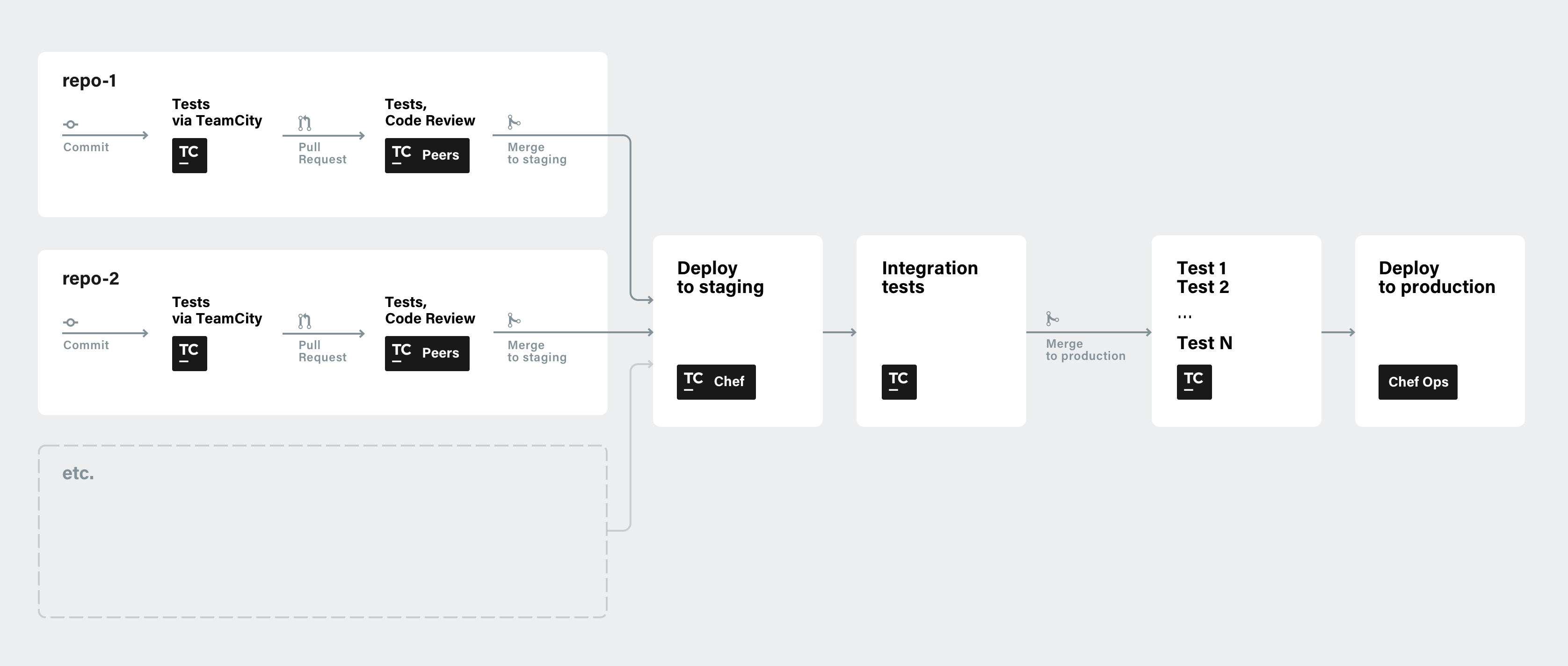 Deployment scheme
Deployment schemeWe get notified about deployment status via a Slack channel. Regarding reports, we get a lot of input from our monitoring stack, which includes Rollbar for reporting errors and exceptions, LogDNA for logging, Pingdom for testing our services externally, Amazon CloudWatch for monitoring AWS stats, Telegraf for collecting metrics and events, Prometheus for consolidating them, and Grafana to visualize the health status of our servers and services. In our stack, we send all alerts to Opsgenie, which groups them, filters the noise, and notifies us using multiple notification channels. To communicate the real-time status of our services to our users, we use Statuspage.
Team administration, tasks, communication
Along with Slack, there's also G Suite for emails. Jira is our primary task manager, but parts of the team can use additional tools for planning, such as Height. Hubspot is our CRM where we monitor the sales pipeline, HelpScout is for customer success communications and client relations, customer.io for automated email campaigns, and more.
Vision
Since we provide a complete set of building blocks for handling files, we encourage everyone out there to use similar building blocks for different parts of their products. Our stack is a great example of that — it's a collection of pre-built components. And we can always go on and add more to the list.
For instance, we use Segment to gather data and send it to other services, such as BigQuery and Amplitude for analysis. We also have Stripe for processing payments, Xero for accounting, and Divvy for managing virtual cards used to pay our vendors.
We practice what we preach: focus on what you want to create, and let those building blocks handle the specific tasks they were made for.
Why spend time and resources on developing and maintaining a file-handling infrastructure when there’s a ready-made proven solution that can be implemented by the end of the day?